
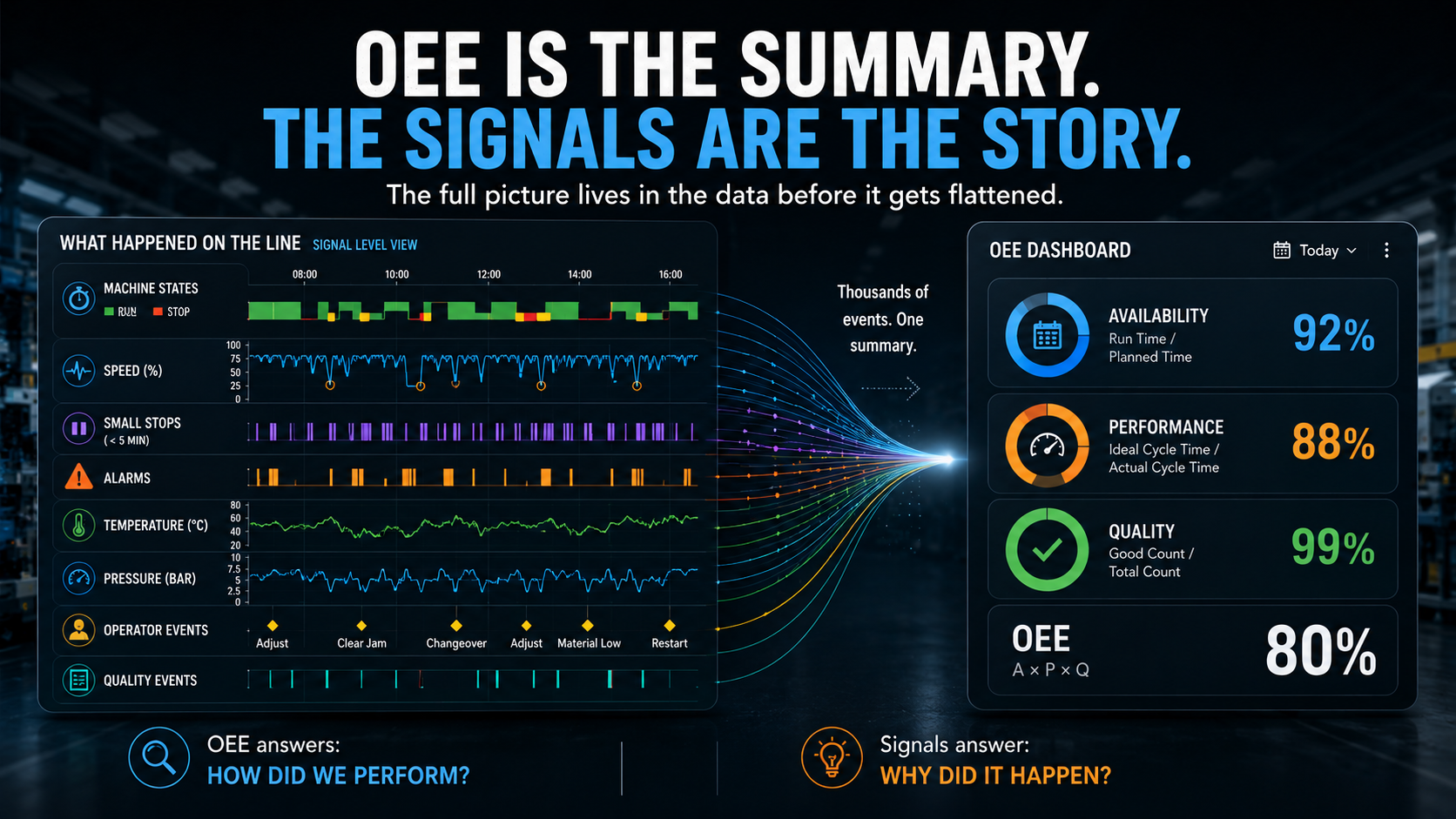
Ihre Maschinen erzeugen Tausende Datenpunkte pro Schicht. Bis diese Daten Ihr Dashboard erreichen, sind sie auf drei Zahlen zusammengeschrumpft – Verfügbarkeit, Leistung, Qualität –, miteinander zu einer einzigen multipliziert. Diese Zahl wird berichtet, geprüft und verwendet, um Entscheidungen über die Produktion zu treffen.
Doch irgendwo zwischen der Maschine und der Kennzahl ist der Großteil der Information verschwunden.
Wie Daten aussehen, bevor sie eingeebnet werden
Eine moderne Produktionsmaschine erlebt eine Schicht nicht als glatten Durchschnitt. Sie erlebt sie als kontinuierlichen Strom von Ereignissen:
Kurze Stopps, Bedienereingriffe, Temperaturschwankungen, Druckabfälle, die sich in Sekunden erholen – jedes davon ist ein Signal. Zusammen erzählen sie eine detaillierte Geschichte darüber, wie sich die Maschine tatsächlich verhält – nicht wie sie im Durchschnitt abschnitt, sondern was sie tat, in welcher Reihenfolge und was jedem Problem vorausging. Diese Geschichte gelangt nicht in den Bericht.
Was die Aggregation entfernt
Wenn rohe Signaldaten zu OEE zusammengefasst werden, geschehen drei Dinge:
Zeit kollabiert. Eine Schicht wird zu einer Summe. Sie verlieren die Abfolge – welche Ereignisse zuerst geschahen, was der Ausfallzeit vorausging, ob der Geschwindigkeitsverlust in einem Fenster konzentriert oder über die ganze Schicht verteilt war usw. Die Zeitachse wird ausgelöscht.
Variation wird herausgemittelt. Eine Maschine, die sechs Stunden mit 100 % und zwei Stunden mit 40 % lief, erzeugt denselben Leistungswert wie eine Maschine, die den ganzen Tag mit 85 % lief. Der Durchschnitt ist identisch, aber die betriebliche Realität ist völlig unterschiedlich.
Kleine Ereignisse verschwinden vollständig. Ein zweiminütiger Stopp, der sich von selbst erholt, taucht in der Verfügbarkeit kaum auf. Eine Zykluszeitabweichung von wenigen Sekunden wird spurlos in die Leistung aufgenommen. Doch diese kleinen Ereignisse sind oft die frühen Indikatoren eines größeren Problems, das sich entwickelt. Bis sie sich genug angesammelt haben, um die OEE-Zahl zu bewegen, ist das Problem nicht mehr im Frühstadium.
Die Lücke zwischen dem, was geschah, und dem, was aufgezeichnet wurde
Das ist der entscheidende Punkt: Ihre Maschinen produzierten die ganze Schicht über Informationen. Signale, die Ihnen – könnten Sie sie in Abfolge und im Kontext sehen – genau sagen würden, wann sich etwas zu verändern begann und wie es aussah, bevor es zum Ausfall wurde.
Die Information überlebte den Aggregationsschritt nicht.
Was Ihr Dashboard erreicht, ist eine komprimierte, gemittelte, aus dem Kontext gerissene Version einer weit reicheren Geschichte.
Was sich ändert, wenn Sie aufhören einzuebnen
Wenn Teams mit Daten auf Signalebene arbeiten statt mit aggregierten Kennzahlen, ist der Zugewinn an Transparenz sofort spürbar.
Sie hören auf zu fragen „Warum war die OEE diese Woche niedrig?“ und sehen die Antwort, bevor die Schicht endet. Sie untersuchen nicht mehr aus einer Zusammenfassung heraus, sondern folgen der tatsächlichen Abfolge der Ereignisse. Sie reagieren nicht mehr auf die Kennzahl, sondern auf das, was die Maschine Ihnen Stunden – manchmal Tage – bevor der Verlust in der Zahl sichtbar wurde, mitgeteilt hat.
OEE ist eine nützliche Zusammenfassung für Berichte, Benchmarking und die Verfolgung des Fortschritts über die Zeit, aber sie ist ein begrenztes Werkzeug, um zu verstehen, was tatsächlich in Ihrer Fertigung geschieht. Sie wurde bewusst zum Zusammenfassen gebaut. Und Zusammenfassen bedeutet, genau die Art von Detail zu verlieren, die frühes Eingreifen möglich macht.
Die Daten waren immer da
Das ist der unbequeme Teil daran.
Die Signale, die den Ausfall hätten vorhersagen, den Qualitätsverlust erklären oder den Verschleiß erkennen können, bevor er zur Ausfallzeit wurde – sie wurden die ganze Zeit erzeugt.
Die Frage ist nicht, ob Ihre Maschinen nützliche Daten produzieren. Die Frage ist, wie viel davon lange genug überlebt, um darauf reagieren zu können.
Want to learn more?
Fallstudien
Wie führende Unternehmen ihre Geschäftstätigkeit transformieren
Beispiele aus der Praxis für betriebliche Exzellenz, die durch unsere Plattform erreicht wurde


